


Making Aftenposten the most resilient digital paper in the Nordics

Aftenposten is one of the largest newspapers in the Nordics. News is vital during emergencies - both national and local. The engineering team behind Aftenposten do their best to ensure that our news is available to readers as often as possible. This ties into a principle that Schibsted news sites try to follow: not that our sites should never go down, but rather when something goes wrong, we recover from it quickly. This is the definition of resilience: to response to things breaking by quickly making things work again.
There's a lot that can go wrong in a big news site. The editor the journalists use to write content might stop working. The content API's servers might go down. The chat service used by journalist might be offline. Our goal is to not prevent all these incidents from happening, but to handle them. It is not possible to account for all the different problems that might go wrong in an organization or in software: this is why resilience is our key.
For a long time, I've been pondering on one big problem: if something catastrophic were to happen to all the papers in Schibsted, how can we ensure that Aftenposten is the first to restore service to readers? Schibsted has many papers across Norway and Sweden, and as a result a lot of the core infrastructure is shared between them. On one hand, this makes bugs across multiple sites easier to fix in one place. No need to update libraries or patch some code in multiple repos, just in one. On the other hand, this often means that if VG has a problem, so does Aftenposten. If any of the centralized services have issues, every paper has issues. A simple example is that if the CMS (content management system) the journalists use to write articles has problems, it affects every journalist we have. This is a natural side effect of centralized services -- which isn't to say that centralized services are bad, but that they do make problems like this more relevant. Centralized services allow a smaller team to maintain a project for multiple different teams with fewer resources. Interestingly, at Omni we didn't have this potential problem to such a large extent: for each of Omni's four products, each product had a complete copy of the stack. There are downsides to this too, like instead of having O(1) services, you now have O(N). But it did mean that each product could be scaled up independently, or handle incidents on a single service affecting a single product.
There is no simple fix - it is both an infrastructure one, as well as a code one. Either you have independent stacks, in which case costs and complexity bloom, or you have a single shared stack, in which case a weakness in one brand is a weakness in all. In reality, only some parts of our stack is shared - meaning we have a combination of shared strong and weak areas, and our own strong and weak areas.
The problem bugged me. During a particular incident where a central service had problems with one of the other brands, Aftenposten was down as a side effect. It was at this point that I decided to make Aftenposten the most resilient digital paper in Schibsted, and I believe in the Nordics.
The goal was simple: at all times, journalists must be able to reach our audience with breaking news stories. That broke the problem down into two parts:
1) Journalists must be able to write articles.
2) Users must be able to read articles.
These two might seem obvious, and well, they are. But it made thinking about the solutions a little easier.
First, writing articles. When everything works as it should, the journalists use a CMS that we have developed internally. This CMS is maintained centrally, and articles published there go through a pipeline which we consume as microservices known as content APIs. We have a few different content APIs, running as different services - mainly so that we can perform different transformations on the content. There's the raw format of the JSON which matches the CMS's internal format, there's one enriched with content for each brand's unique needs. There's a few more but those are basically the extremes at each end. These content APIs are then consumed by layers converting content into HTML: articles, frontpages, and section pages. They're also consumed by the apps, in the enriched format.
Back to our two problems: if the CMS goes down, journalists aren't able to write anything. If the content APIs or rendering layers go down, then the readers can't read anything.
Solving the rendering layer problem, I wrote an alternative frontend renderer in Derw which used a simplified standardised format, a little simpler than the full content API. This rendered was intended to be lightweight and small, while being type safe so there'd be no need to worry about things breaking in production. To be distributable as a single file, all styles are inlined into the HTML file. There's no client side JavaScript, and images are also inlined as base64. There are two output formats: one where every included article is on one long, continuous page so that every article can be distributed at once. The first so that every article can be distributed at once. The other would create screenshots of each article, so that articles can be distributed as images - via social media. The styling was mostly borrowed from Aftenposten's regular website, with some changes to make things fit the new layout.


You might ask why use Derw here? Well, just rendering part is in Derw. The rendering is very simple - it just takes the data source, then server-side render some static HTML. At any point, if there is additional complexity required, it will be trivial to either keep in Derw or rewrite. Derw’s interop with TypeScript makes it very easy to move around as required - along with a TypeScript generator making it easy to just replace Derw with the generated TS. All that said, Derw provides some great advantages to these types of projects. You’re likely to work on these projects on and off over a long time period with gaps in between, and having a well-typed language with a small and fast runtime helps with familiarising with the project.
As mentioned, there are multiple different internal content APIs - and I wrote a transform for them all, into the simplified format. This means that now we could use normal, production data with these frontend renderers.
Many news publications have backup a CMS. WordPress, gatsby, there's a lot of great options out there. But I'm a firm believer that the best tool is the tool you have available. Our journalists all have access to Google Docs, and frequently use it. The first step in my solution therefore was to make Google Docs a CMS that would produce content in a compatible format as our content APIs. This was quite simple - first I wrote a fetcher that would grab all Google Docs in a specific folder. Then each Doc would be converted into the simplified format. And this is the result:
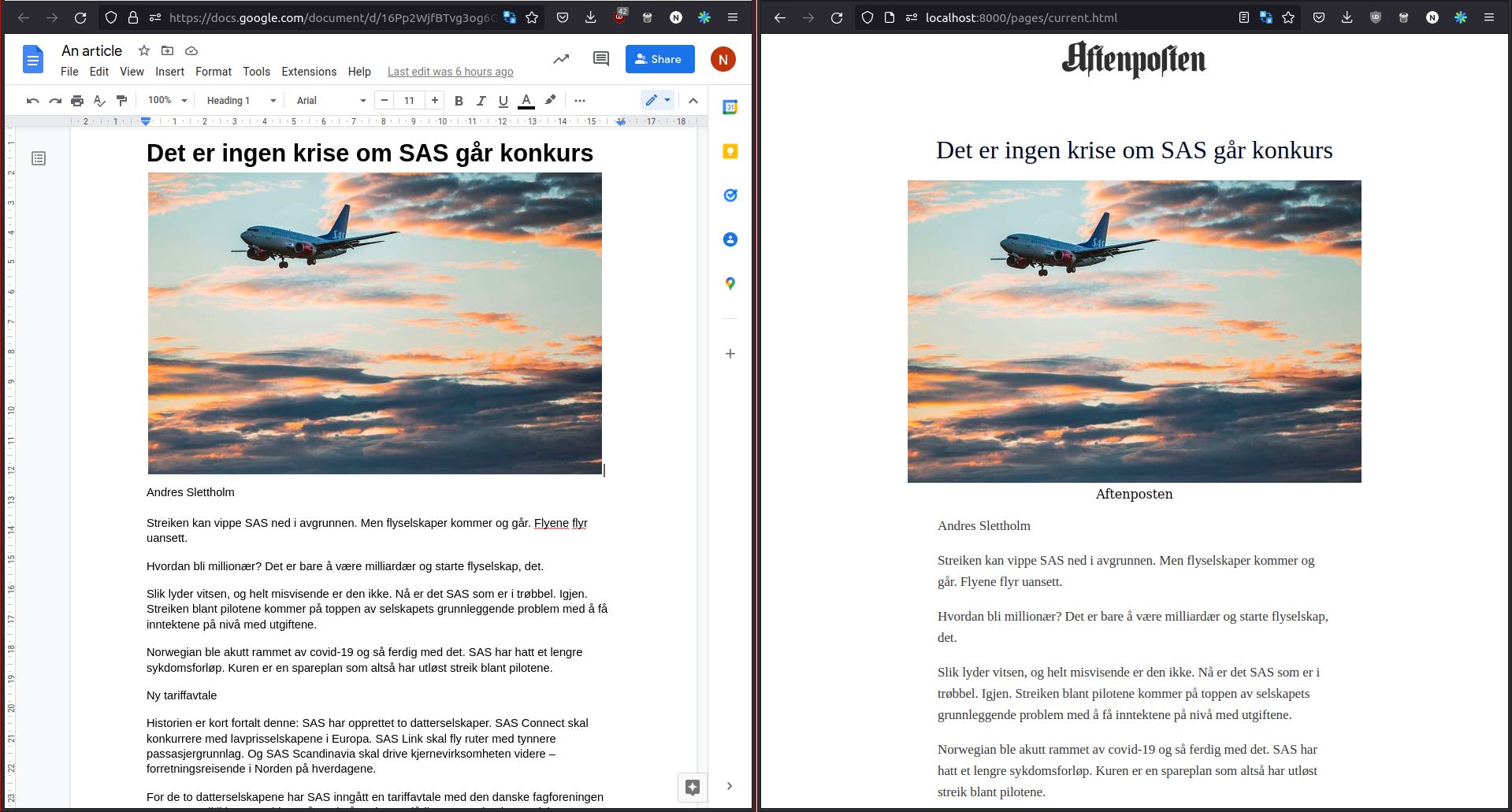
Then it came to me. Where else do the journalists spend a lot of their time? On the work communication tool! So I set up a channel where any post would be added to the article feed, in reverse order (i.e newest posts first). Slack's formatting is not quite suited to this usage, so it ends up with a mismatch between how it looks in Slack vs the actual article, but you can see the effect here:
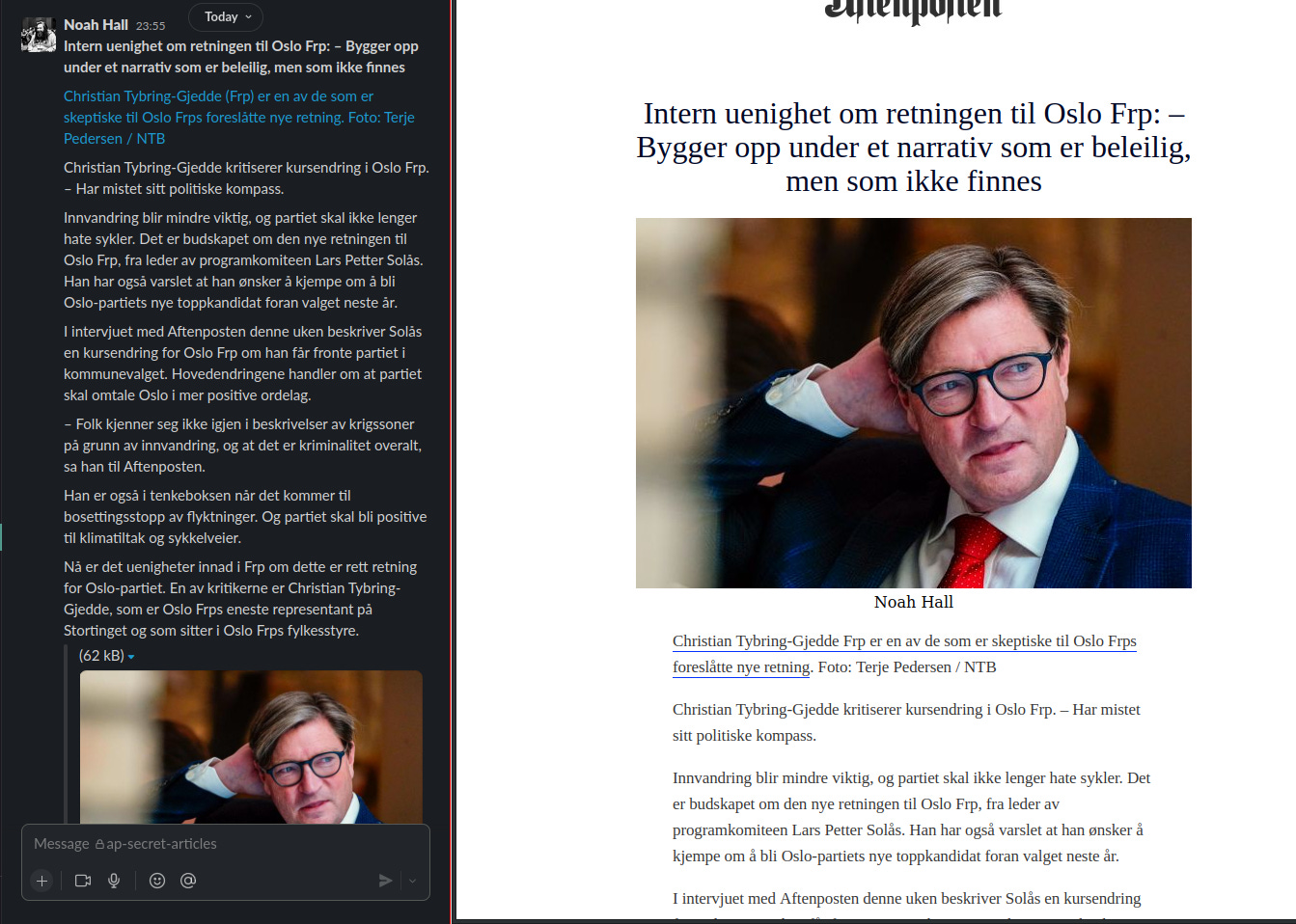
Finally, what better way to write articles than to just use plain text? Well, using markdown is one improvement over that. The idea being that in a crisis, if everything is broken, developers should be in touch with journalists to help guide them. So that's what I did. All text files within a folder can be turned into an article feed, with a prefix to the name in order to insert the article in a different place (i.e 0-article.md would be at the top). It looks a little like this:
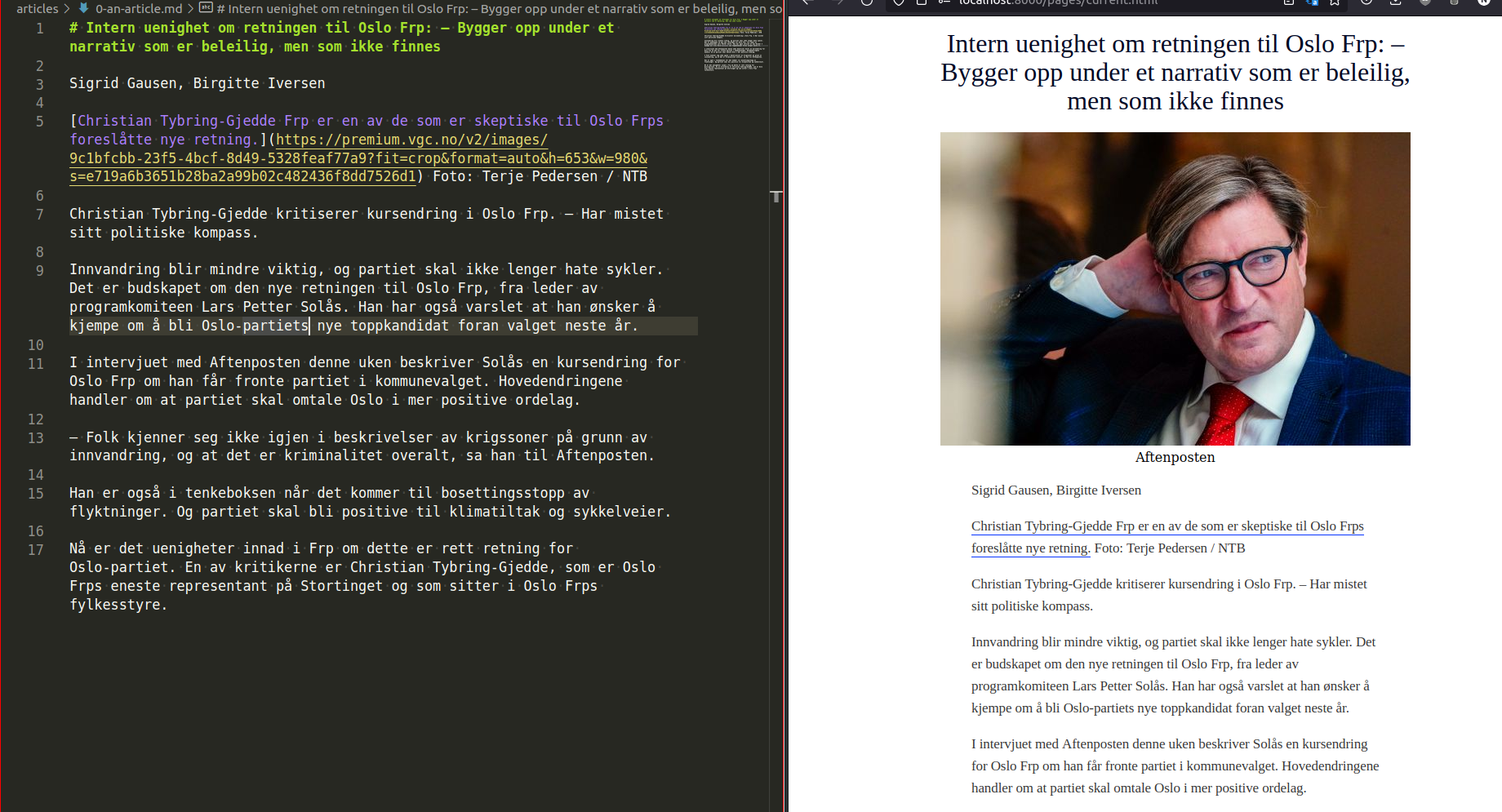
That gives us three alternative CMSs: Google Docs, Slack and text files. Backed up by the content APIs when they are online, this led to a total of 4 different ways of writing articles, and 6 different possible sources for feeds. This meant the "writing an article" part of the problem was now resilient - along with a way of producing readable content for the users. But there was still a need to actually distribute the rendered feed. To do this, we hooked up several CDNs and alternative hosts. My favourite part is that we have a script that will take the rendered HTML, and inline it into a varnish config so that it's possible to do synth responses without hitting any servers other than the varnish server. This effectively means that if something happens, we're now able to produce content in several ways, render it, and distribute it to our readers.
All this work was done relatively quickly, and is now in use in a couple of the Schibsted brands. Preparing for the worst is an important exercise - not just in terms of making something usable, but also as a thought exercise. If AWS goes down, what do we do? If the CMS goes down, what do we do? If the internet generally goes down, what do we do? I encourage every team to spend at least a little time in disaster planning - if nothing else, you get a cool blog post out of it.
Making a site resilient is all about these thought exercises. It’s not possible to solve every problem before it happens. But you can prepare the mindset of your team to handle these incidents in a way that allows for a quick turnaround when things go wrong.